Cramfiles
- 30 Dec 2024
Cramfiles
Sparse Matrices:
A sparse matrix is a matrix where most of the elements are zero. For example a social network contains a lot of nodes but not every node is connected to only a few others.
In contrast a dense matrix is a matrix in which most elements are non zero. For example pixel data from an image, where each pixel usually has a non zero value. For every matrix sparsity can be calculated as
Sparsity = Number of zero elements / Number of non zero elements
Mathematically sparse matrices are just normal matrices, but can be represented in a computationally efficient way by not storing the locations of the zero elements.
There are several ways to approach this.
- COO - Coordinate list : In this format we have a list, in which the elements are <row, column, values> of the non zero elements. The size of the list is equal to the number of non zero elements in the matrix
- CSR and CSC : Compressed Sparse Row (CSR) and Compressed Sparse Column (CSC) are formats that compress the matrix into a 1d list.
- For CSR the list has three list a value list, a column index list and a row index list. Each of the rows are compressed to provide a list which corresponds to the elements in the column list. eg: we have a matrix 95 33 0 0 0 12 11 0 0 This can be expressed in CSR as Values = [95, 33, 12, 11] columns = [0, 1, 2, 1] rows = [0, 2, 3, 4] as you can see, the row list is always incrementing and point to the column values list. The row list can be thought of as python like index ranges with which you can iterate and get the particular values.
- LIL - List of Lists. We have one large list where each element is another list for each row of the matrix and the nested list contains the column index and the value.
There are a few packages that are available. I personally deal with Hi-C matrices which are very sparse in nature and the common data formats used are cool and mcool. These files store the matrix in COO format.
For my specific use case I had to access random rows from the matrix and do it multiple times. The problem with cool and other formats is that the files are compressed and every time you want to access a particular element/row/column, you have to load the entire matrix into memory and then access the values. This means that if your matrix is really huge ( which is the case with hi resolution Hi-C matrices ) The uncompressed files come to around 25 GB, which means we will have to use 25 GB of memory to load a bunch of elements which will in total won’t come to a couple of Megabytes in size.
To solve this, I decided to create a new format CRAM - Compressed Row Access Matrix format which handles the tradeoff between loading time and storage space. By increasing the storage space by a little, you can get really good random access without increasing memory pressure.
How it works
Compressed Sparse Rows and Compressed Sparse Columns basically have a really good data structure to solve this particular problem. For example in CSR, the Row list is a naturally increasing range which tracks the location of elements in the other two lists in an efficient way. We will use this feature of the CSR to write it to memory.
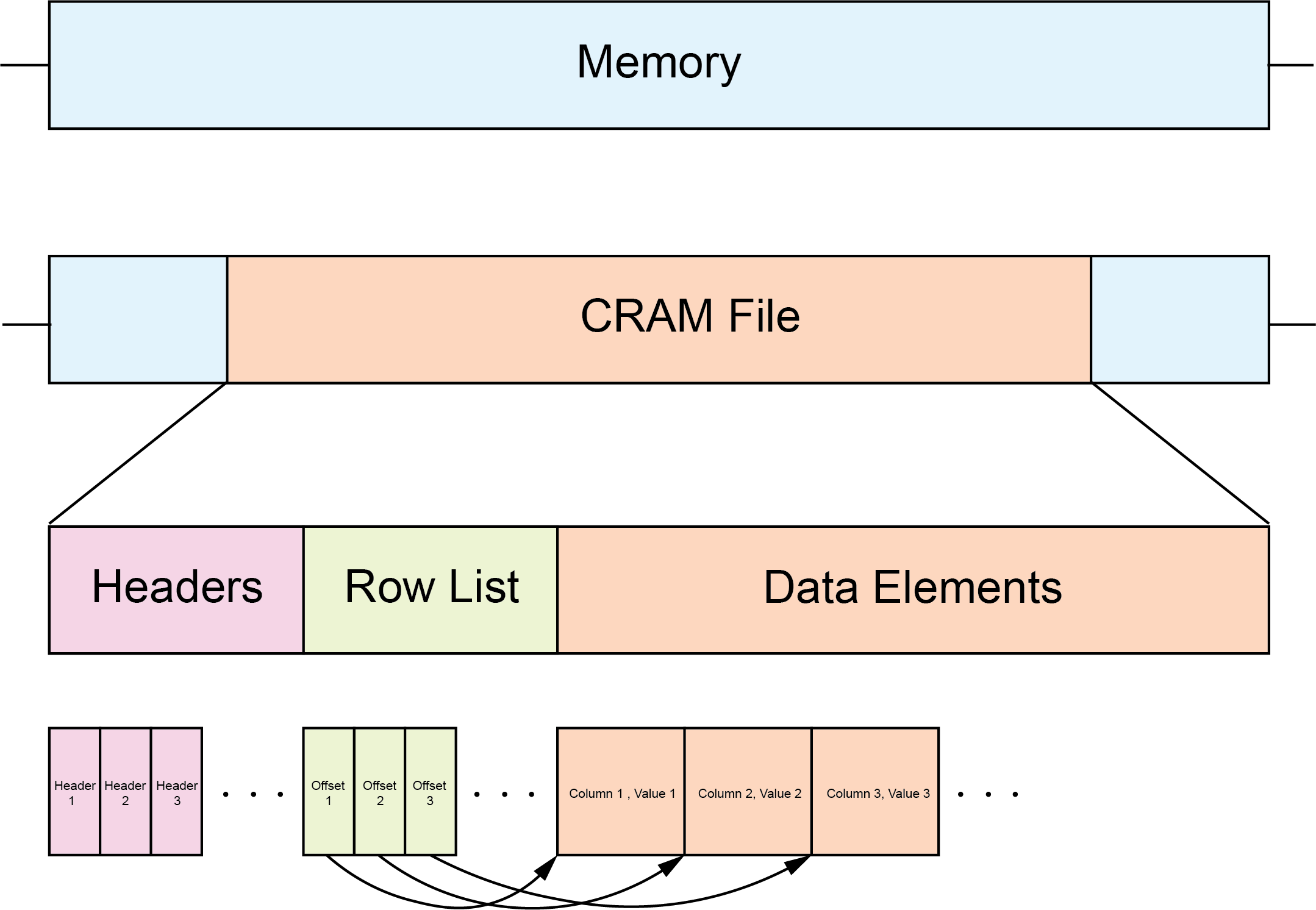
Approaching this as a pure engineering problem, a file is a collection of bytes that will be stored on the computer’s memory. each part of the file will have it’s own pointer which.
This works by counting from the start of the file, the next n bytes will contain the Row list. But instead of a normal Row list, we store the bit location to shift from the start of the data to fetch the values from the matrix. So we essentially know the start and end of the Row list. each element in the row list tells us how much to move from the end of the Row list to get to the actual data element. Each data element in turn has the column number and the value, which we know exactly how to fetch.
This is a slight simplification, in reality, we have some header elemnts holding metadata about the matrix which we also know the size of, and we also know the exact size of each element in the matrix.
Why
The idea was greatly influenced by DICOM files, which use a similar approach for tag parsing. This seems like a trivial application of an abstract concept, but improves the performance of loading and cuts down memory requirements by a huge amount. The key takeaway is to know the application and the type of data you are going to use and think of smart ways to take advantage of their structure.
Links
CRAM repository - Github repository with the package implementing the above mentioned idea